HashMap
底层为内部类 Node 的数组 + 链表 HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),假设有 hash 碰撞,进行 == 或 equals 判断,替换或加入链表。1.8 之后为了优化链表阶段的查询速度,在数量超过 8 之后改用红黑树结构。内部以 Node 节点储存,Node 继承自 LinkedHashMap 的 Entry,增加了前后查找的方法,方便少于 8 个时再退化为普通 Node 组成链表
长度扩容,新 HashMap 在设置容量时会按照 2 的幂次放进行设置,是由于 HashMap 通过 key 的 hash 对数组长度取模之后得到的 value 存放位置,取模运算在除数等于 2 的幂次方时可以被优化为二进制运算,速度更快,也就是 hash%length==hash&(length-1) 的前提是 length 是 2 的 n 次方 ,因此这样设置容量可以提升性能。
判断 hash 碰撞,是否存取的目标的判断条件
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
扩容
默认初始大小 16,扩展为每次 2 倍大小,扩展阈值为总量的 75%,总容量总是为 2 的幂次方。扩容方法为 resize,扩容时会调整哈希桶的数据结构,桶上元素大于等于 8 且数组长度大于等于 64 则变更为红黑树,小于等于 6 则退化为链表。
缺点
HashMap 的数组只会扩容不会缩小,就算 remove 所有键值对后,size 值会变化,但数组还是原来的长度,因此比较占用内存。
1.7 版本中的死循环问题
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
// 下面这段代码的意思是:
// 从 OldTable 里摘一个元素出来,然后放到 NewTable 中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
由以下 2 个原因触发
- 多个线程竞争进行 rehash
- rehash 放置链表元素时,会将元素顺序倒转
具体过程
- 线程 1 执行到
Entry<K,V> next = e.next;完成指向后等待 - 其他线程执行完成了 rehash 动作
- 此时 e 和 e.next 已经在新链表上被倒转位置,线程 1 的 rehash 动作又将他们倒转并且互相指向
- 后面这 2 个元素由于互相指向 next 就会循环引用
1.8 版本修复死循环的方法
摘自: 美团技术团队 - Java 8 系列之重新认识 HashMap
下面我们讲解下 JDK1.8 做了哪些优化。经过观测可以发现,我们使用的是 2 次幂的扩展 (指长度扩为原来 2 倍),所以,元素的位置要么是在原位置,要么是在原位置再移动 2 次幂的位置。看下图可以明白这句话的意思,n 为 table 的长度,图(a)表示扩容前的 key1 和 key2 两种 key 确定索引位置的示例,图(b)表示扩容后 key1 和 key2 两种 key 确定索引位置的示例,其中 hash1 是 key1 对应的哈希与高位运算结果。
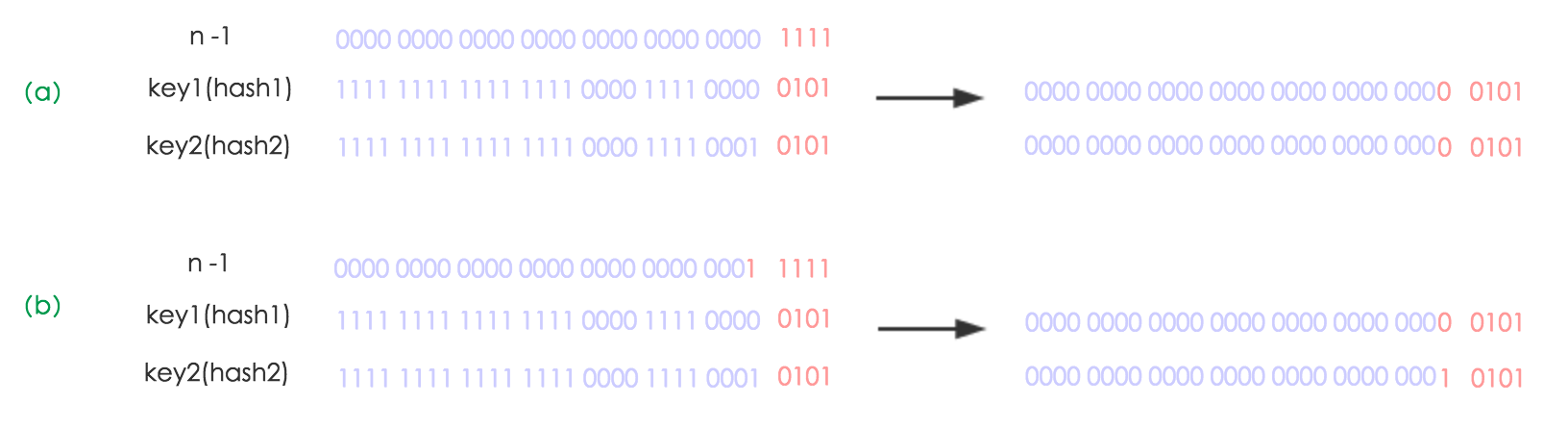
元素在重新计算 hash 之后,因为 n 变为 2 倍,那么 n-1 的 mask 范围在高位多 1bit(红色),因此新的 index 就会发生这样的变化:
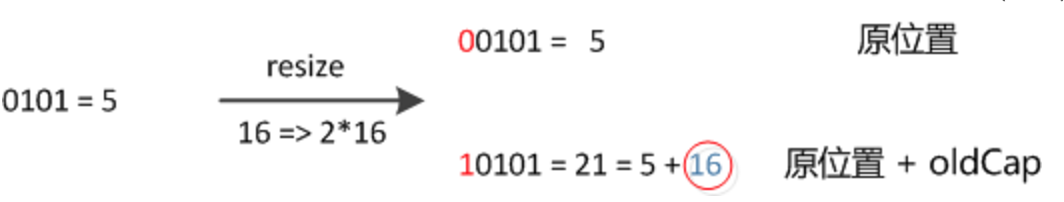
因此,我们在扩充 HashMap 的时候,不需要像 JDK1.7 的实现那样重新计算 hash,只需要看看原来的 hash 值新增的那个 bit 是 1 还是 0 就好了,是 0 的话索引没变,是 1 的话索引变成 “原索引 + oldCap”,可以看看下图为 16 扩充为 32 的 resize 示意图:

ConcurrentHashMap
1.7 版本底层是 Segment[],Segment 本身继承 ReentrantLock,实现了分段锁功能,内部是 HashEntry 数组,HashEntry 节点可以组成链表。
1.8 版本取消 Segment 设计,使用 CAS 和 synchronized 关键字保证并发安全,synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。
ArrayList
底层为 Object[],继承自 AbstractList, 实现了 List, RandomAccess, Cloneable, java.io.Serializable 这些接口。默认初始容量 10,每次扩容 1.5 倍。每次添加内容都要通过 ensureCapacityInternal 确认数组是否够大。可以通过 trimToSize 缩小数组大小到当前当前内容的长度,内部实现是 Arrays.copyOf。remove 方法后需要移动数组内容,内部实现是 System.arraycopy(elementData, index+1, elementData, index,numMoved);
/**
* ArrayList 扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity 为旧容量,newCapacity 为新容量
int oldCapacity = elementData.length;
// 将 oldCapacity 右移一位,其效果相当于 oldCapacity /2,
// 我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的 1.5 倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 再检查新容量是否超出了 ArrayList 所定义的最大容量,
// 若超出了,则调用 hugeCapacity() 来比较 minCapacity 和 MAX_ARRAY_SIZE,
// 如果 minCapacity 大于 MAX_ARRAY_SIZE,则新容量则为 Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
LinkedList
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
通过内部类 Node 实现双端队列,只保留首端和尾端的节点。查找具体位置的元素时,判断位置是处于前半段还是后半段,从对应方向开始遍历。
TreeMap
红黑树的 NavigableMap 实现,可查找,可排序
HashSet
基于 HashMap 实现,内容储存在键值对的 key 上,value 部分为一个静态的空对象。特点是唯一性,相同元素会覆盖旧的,可以用来去重
TreeSet
默认用 TreeMap 实现,内部以 NavigableMap 作为委托,特点是有序且唯一
LinkedHashMap
在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。在一些场景下,该特性很有用,比如缓存。在实现上,LinkedHashMap 很多方法直接继承自 HashMap,仅为维护双向链表覆写了部分方法。在每次生成新 Node 时,通过下面的 linkNodeLast 方法,连接到双向列表尾部,调用父类方法移除节点后,通过复写 afterNodeRemoval 方法删除双向链表中的引用。
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
排序逻辑和 LRU Cache
默认按照插入顺序排序,在初始化 LinkedHashMap 时,指定 accessOrder 参数为 true,即可让它按访问顺序维护链表,在调用 get/getOrDefault/replace 等方法时,只需要将这些方法访问的节点移动到链表的尾部即可。在这个前提下,只要在插入新节点后,判断内容的总长度,超过指定值后删除双向链表的首节点,就实现了一个简单的 LRU Cache 。